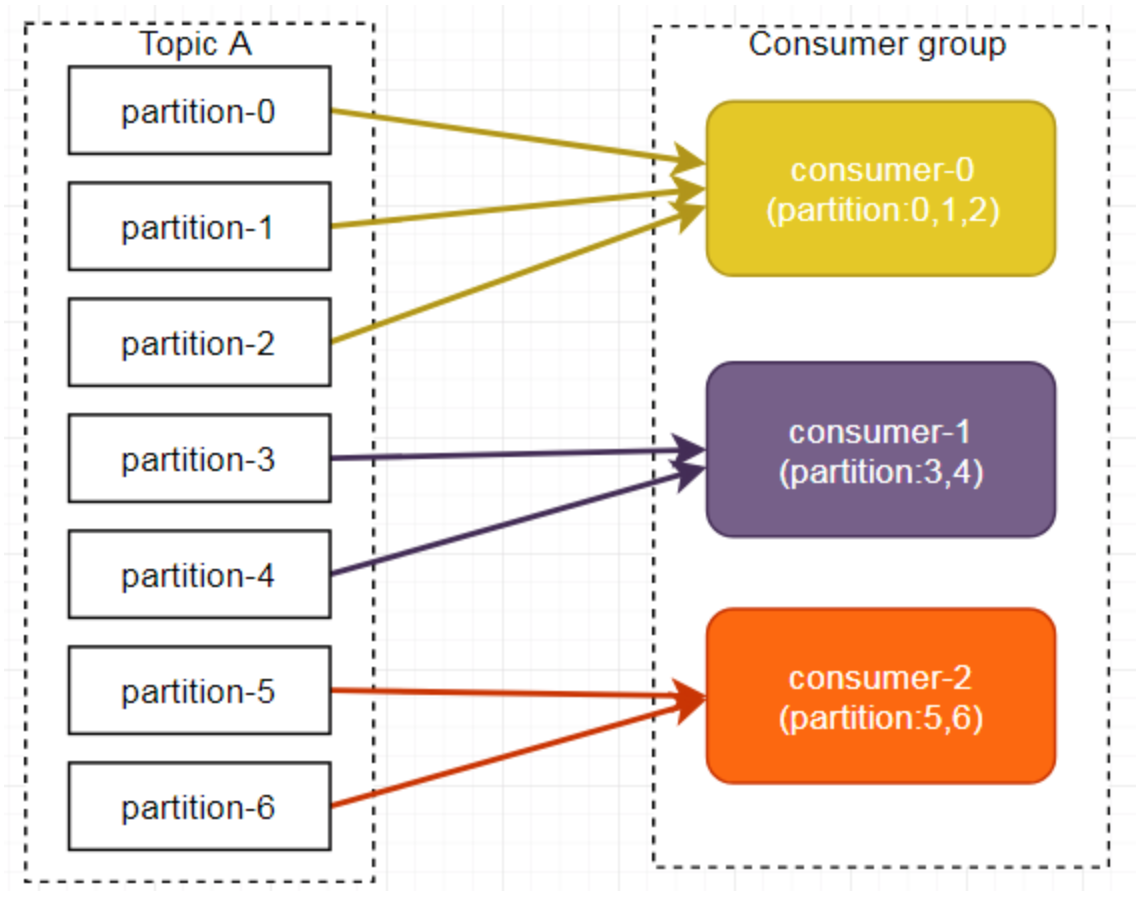
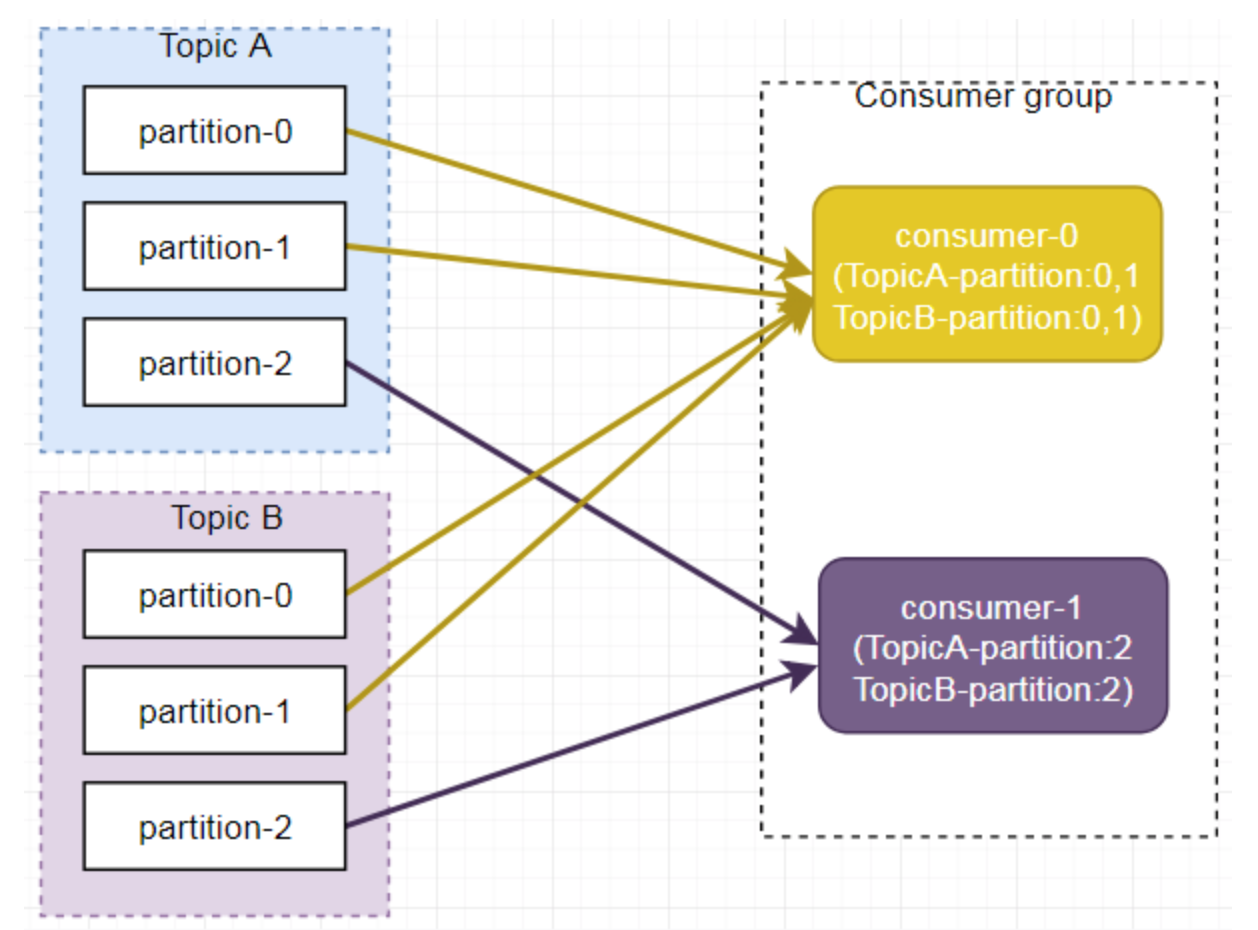
安装 supervisor 参考 supervisor安装
创建并编辑 /etc/supervisord.d/kafka.ini 文件,内容如下:
[program:kafka]
command=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
environment=JMX_PORT=9999
process_name=%(program_name)s
numprocs=1
directory=/opt/kafka/
autostart=true
autorestart=true
startsecs=10
startretries=5
user=root
redirect_stderr=false
stdout_logfile=/var/log/supervisor/kafka.log
stdout_logfile_maxbytes=100MB
stdout_logfile_backups=10
stdout_capture_maxbytes=10MB
stdout_events_enabled=false
stderr_logfile=/var/log/supervisor/kafka_error.log
stderr_logfile_maxbytes=1MB
stderr_logfile_backups=5
stderr_capture_maxbytes=1MB
载入新加的 kafka.ini配置文件
supervisorctl update
)