饮食方面
- 早餐以燕麦片为主,少吃面包(一周最多吃两次),如果喝牛奶的话就以脱脂牛肉为主,不喝豆浆
- 午餐以米饭为辅,多吃蔬菜。少吃肉类(每周吃肉次数不能超过2次)
- 晚餐以米饭为辅,多吃蔬菜.
- 少吃面(一周不超过2次,吃的话重量不能大于二两)
- 每天都要吃一个猕猴桃或者挤橙
- 不吃或者少吃火锅和串串(即使吃的时候也尽量少吃)
- 少吃油腻及煎烤类食物,不吃动物内脏、鱼卵、蟹黄、海鱼、豆类、香菇
锻炼方面
- 每周运动次数不少于4次
- 每次运动不少于30分钟
- 以有氧运动为主
惩罚
- 做不到任凭老婆大人打骂
原地址: https://developer.aliyun.com/article/740242?utm_content=g_1000095371
ABS(x) --返回x的绝对值
BIN(x) --返回x的二进制(OCT返回八进制,HEX返回十六进制)
CEILING(x) --返回大于x的最小整数值
EXP(x) --返回值e(自然对数的底)的x次方
FLOOR(x) --返回小于x的最大整数值
GREATEST(x1,x2,...,xn)
--返回集合中最大的值
LEAST(x1,x2,...,xn)
--返回集合中最小的值
LN(x) --返回x的自然对数
LOG(x,y) --返回x的以y为底的对数
MOD(x,y) --返回x/y的模(余数)
PI() --返回pi的值(圆周率)
RAND() --返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。
ROUND(x,y) --返回参数x的四舍五入的有y位小数的值
SIGN(x) --返回代表数字x的符号的值
SQRT(x) --返回一个数的平方根
TRUNCATE(x,y) --返回数字x截短为y位小数的结果
AVG(X) --返回指定列的平均值
COUNT(X) --返回指定列中非NULL值的个数
MIN(X) --返回指定列的最小值
MAX(X) --返回指定列的最大值
SUM(X) --返回指定列的所有值之和
GROUP_CONCAT(X) --返回由属于一组的列值连接组合而成的结果,非常有用
ASCII(char) --返回字符的ASCII码值
BIT_LENGTH(str) --返回字符串的比特长度
CONCAT(s1,s2...,sn)
--将s1,s2...,sn连接成字符串
CONCAT_WS(sep,s1,s2...,sn)
--将s1,s2...,sn连接成字符串,并用sep字符间隔
INSERT(str,x,y,instr)
--将字符串str从第x位置开始,y个字符长的子串替换为字符串instr,返回结果
FIND_IN_SET(str,list)
--分析逗号分隔的list列表,如果发现str,返回str在list中的位置
LCASE(str)或LOWER(str)
--返回将字符串str中所有字符改变为小写后的结果
LEFT(str,x) --返回字符串str中最左边的x个字符
LENGTH(s) --返回字符串str中的字符数
LTRIM(str) --从字符串str中切掉开头的空格
POSITION(substr,str)
--返回子串substr在字符串str中第一次出现的位置
QUOTE(str) --用反斜杠转义str中的单引号
REPEAT(str,srchstr,rplcstr)
--返回字符串str重复x次的结果
REVERSE(str) --返回颠倒字符串str的结果
RIGHT(str,x) --返回字符串str中最右边的x个字符
RTRIM(str) --返回字符串str尾部的空格
STRCMP(s1,s2) --比较字符串s1和s2
TRIM(str) --去除字符串首部和尾部的所有空格
UCASE(str)或UPPER(str)
--返回将字符串str中所有字符转变为大写后的结果
CURDATE()或CURRENT_DATE()
--返回当前的日期
CURTIME()或CURRENT_TIME()
--返回当前的时间
DATE_ADD(date,INTERVAL int keyword)
--返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化)
例如
SELECT DATE_ADD(CURRENT_DATE,INTERVAL 6 MONTH);
DATE_FORMAT(date,fmt)
--依照指定的fmt格式格式化日期date值
DATE_SUB(date,INTERVAL int keyword)
--返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化)
例如
SELECT DATE_SUB(CURRENT_DATE,INTERVAL 6 MONTH);
DAYOFWEEK(date) --返回date所代表的一星期中的第几天(1~7)
DAYOFMONTH(date) --返回date是一个月的第几天(1~31)
DAYOFYEAR(date) --返回date是一年的第几天(1~366)
DAYNAME(date) --返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE);
FROM_UNIXTIME(ts,fmt)
--根据指定的fmt格式,格式化UNIX时间戳ts
HOUR(time) --返回time的小时值(0~23)
MINUTE(time) --返回time的分钟值(0~59)
MONTH(date) --返回date的月份值(1~12)
MONTHNAME(date) --返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE);
NOW() --返回当前的日期和时间
QUARTER(date) --返回date在一年中的季度(1~4)
例如
SELECT QUARTER(CURRENT_DATE);
WEEK(date) --返回日期date为一年中第几周(0~53)
YEAR(date) --返回日期date的年份(1000~9999)
例如,获取当前系统时间
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP());
SELECT EXTRACT(YEAR_MONTH FROM CURRENT_DATE);
SELECT EXTRACT(DAY_SECOND FROM CURRENT_DATE);
SELECT EXTRACT(HOUR_MINUTE FROM CURRENT_DATE);
返回两个日期值之间的差值(月数)
SELECT PERIOD_DIFF(200302,199802);
在Mysql中计算年龄:
SELECT DATE_FORMAT(FROM_DAYS(TO_DAYS(NOW())-TO_DAYS(birthday)),'%Y')+0 AS age FROM employee;
这样,如果Brithday是未来的年月日的话,计算结果为0。
下面的SQL语句计算员工的绝对年龄,即当Birthday是未来的日期时,将得到负值。
SELECT DATE_FORMAT(NOW(), '%Y')
- DATE_FORMAT(birthday, '%Y')
-(DATE_FORMAT(NOW(), '00-%m-%d')
< DATE_FORMAT(birthday, '00-%m-%d')) AS age from employee
AES_ENCRYPT(str,key)
--返回用密钥key对字符串str利用高级加密标准算法加密后的结果,调用AES_ENCRYPT的结果是一个二进制字符串,以BLOB类型存储
AES_DECRYPT(str,key)
--返回用密钥key对字符串str利用高级加密标准算法解密后的结果
DECODE(str,key) --使用key作为密钥解密加密字符串str
ENCRYPT(str,salt) --使用UNIXcrypt()函数,用关键词salt(一个可以惟一确定口令的字符串,就像钥匙一样)加密字符串str
ENCODE(str,key) --使用key作为密钥加密字符串str,调用ENCODE()的结果是一个二进制字符串,它以BLOB类型存储
MD5() --计算字符串str的MD5校验和
PASSWORD(str) --返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。
SHA() --计算字符串str的安全散列算法(SHA)校验和
例如
SELECT ENCRYPT('root','salt');
SELECT ENCODE('xufeng','key');
SELECT DECODE(ENCODE('xufeng','key'),'key');#加解密放在一起
SELECT AES_ENCRYPT('root','key');
SELECT AES_DECRYPT(AES_ENCRYPT('root','key'),'key');
SELECT MD5('123456');
SELECT SHA('123456');
CASE WHEN [test1] THEN [result1]...ELSE [default] END
--如果test1是真,则返回result1,否则返回default
CASE [test] WHEN [val1] THEN [result]...ELSE [default] END
--如果test和valN相等,则返回result,否则返回default
IF(test,t,f) --如果test是真,返回t;否则返回f
IFNULL(arg1,arg2) --如果arg1不是空,返回arg1,否则返回arg2
NULLIF(arg1,arg2) --如果arg1=arg2返回NULL;否则返回arg1
这些函数的第一个是IFNULL(),它有两个参数,并且对第一个参数进行判断。
如果第一个参数不是NULL,函数就会向调用者返回第一个参数;
如果是NULL,将返回第二个参数。
例如
SELECT IFNULL(1,2),
IFNULL(NULL,10),
IFNULL(4*NULL,'false');
NULLIF()函数将会检验提供的两个参数是否相等,如果相等,则返回NULL,
如果不相等,就返回第一个参数。
例如
SELECT NULLIF(1,1),
NULLIF('A','B'),
NULLIF(2+3,4+1);
MySQL的IF()函数也可以建立一个简单的条件测试,
这个函数有三个参数,第一个是要被判断的表达式,
如果表达式为真,IF()将会返回第二个参数,
如果为假,IF()将会返回第三个参数。
例如
SELECT IF(1<10,2,3),IF(56>100,'true','false');
IF()函数在只有两种可能结果时才适合使用。
然而,在现实世界中,我们可能发现在条件测试中会需要多个分支。
在这种情况下,它和PHP及Perl语言的switch-case条件例程一样。
CASE函数的格式有些复杂,通常如下所示:
CASE [expression to be evaluated]
WHEN [val 1] THEN [result 1]
WHEN [val 2] THEN [result 2]
WHEN [val 3] THEN [result 3]
......
WHEN [val n] THEN [result n]
ELSE [default result]
END
这里,第一个参数是要被判断的值或表达式,接下来的是一系列的WHEN-THEN块,
每一块的第一个参数指定要比较的值,如果为真,就返回结果。
所有的WHEN-THEN块将以ELSE块结束,当END结束了所有外部的CASE块时,
如果前面的每一个块都不匹配就会返回ELSE块指定的默认结果。
如果没有指定ELSE块,而且所有的WHEN-THEN比较都不是真,MySQL将会返回NULL。
CASE函数还有另外一种句法,有时使用起来非常方便,如下:
CASE
WHEN [conditional test 1] THEN [result 1]
WHEN [conditional test 2] THEN [result 2]
ELSE [default result]
END
这种条件下,返回的结果取决于相应的条件测试是否为真。
例如:
SELECT CASE 'green'
WHEN 'red' THEN 'stop'
WHEN 'green' THEN 'go' END;
SELECT CASE 9
WHEN 1 THEN 'a'
WHEN 2 THEN 'b' ELSE 'N/A' END;
SELECT CASE WHEN (2+2)=4 THEN 'OK'
WHEN (2+2)<>4 THEN 'not OK' END AS STATUS;
SELECT Name,IF((IsActive = 1),'已激活','未激活') AS RESULT
FROM UserLoginInfo;
SELECT fname,lname,(math+sci+lit) AS total,
CASE WHEN (math+sci+lit) < 50 THEN 'D'
WHEN (math+sci+lit) BETWEEN 50 AND 150 THEN 'C'
WHEN (math+sci+lit) BETWEEN 151 AND 250 THEN 'B'
ELSE 'A' END AS grade FROM marks;
SELECT IF(ENCRYPT('sue','ts')=upass,'allow','deny') AS LoginResult
FROM users WHERE uname = 'sue';
DATE_FORMAT(date,fmt)
--依照字符串fmt格式化日期date值
FORMAT(x,y) --把x格式化为以逗号隔开的数字序列,y是结果的小数位数
INET_ATON(ip) --返回IP地址的数字表示
INET_NTOA(num) --返回数字所代表的IP地址
TIME_FORMAT(time,fmt)
--依照字符串fmt格式化时间time值
其中最简单的是FORMAT()函数,
它可以把大的数值格式化为以逗号间隔的易读的序列。
例如
SELECT FORMAT(34234.34323432,3);
SELECT DATE_FORMAT(NOW(),'%W,%D %M %Y %r');
SELECT DATE_FORMAT(NOW(),'%Y-%m-%d');
SELECT DATE_FORMAT(19990330,'%Y-%m-%d');
SELECT DATE_FORMAT(NOW(),'%h:%i %p');
SELECT INET_ATON('10.122.89.47');
SELECT INET_NTOA(175790383);
为了进行数据类型转化,MySQL提供了CAST()函数,
它可以把一个值转化为指定的数据类型。
类型有:BINARY,CHAR,DATE,TIME,DATETIME,SIGNED,UNSIGNED
例如
SELECT CAST(NOW() AS SIGNED INTEGER),CURDATE()+0;
SELECT 'f'=BINARY 'F','f'=CAST('F' AS BINARY);
DATABASE() --返回当前数据库名
BENCHMARK(count,expr)
--将表达式expr重复运行count次
CONNECTION_ID() --返回当前客户的连接ID
FOUND_ROWS() --返回最后一个SELECT查询进行检索的总行数
USER()或SYSTEM_USER()
--返回当前登陆用户名
VERSION() --返回MySQL服务器的版本
例如
SELECT DATABASE(),VERSION(),USER();
SELECTBENCHMARK(9999999,LOG(RAND()*PI()));#
该例中,MySQL计算LOG(RAND()*PI())表达式9999999次。
原地址: https://www.linuxtechi.com/htop-monitor-linux-system-processes/
htop是hop命令的一个升级版实用命令。她展示了重要的系统参数,比如正在运行的任务,pids,开机时间,平均负载,内存使用和其他重要的统计负载。在展示系统参数方面,相比于她前一个hop命令htop有更高效的组织方式和变化的色彩方案。比起文本化和繁琐的top命令htop更能让用户能直观的找到他们想要的系统度量。在这篇文章中我们会展示怎样使用大多数htop命令来检索变化的系统度量。htop能在所有的linux发行版中工作,在大多数最新的版本中htop命令默认已经被预装。展示系统度量,紧紧需要输入一个简单的htop命令即可
htop
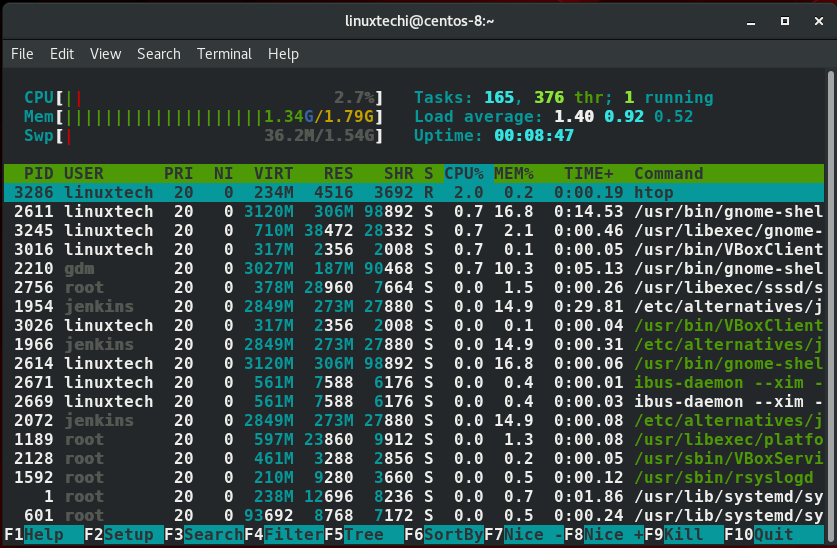
从刚刚的照片输出中,我们能清楚看到htop展示了3个区域:
头部区域展示了系统的cpu 内存 虚拟内存使用量 运行的任务数量 平均负载和开机时间等度量。

这个区域列出了所有正在运行的进程

这部分展示了htop的菜单选项

相比于top命令htop命令包括如下高级用法
1. 能使用鼠标与htop命令交互.
2. 系统度量都用颜色标示能让你更容易的辨别.
3. htop提供了不需要引用pid就能杀死进程的方式.
4. 你能使用鼠标滑上滑下也能使用上下键来查看所有运行的进程.
apt install htop
yum install htop
dnf install htop
现在让我们换个档位,看看htop实用工具提供的各种选项
htop提供多种选项来对你的输出内容进行排序。使用F6功能键就能查看输出选项。在出来的左边选项中,滑动选择你想要对输出排序的条件,默认情况下是使用 PERCENT_CPU 选项。
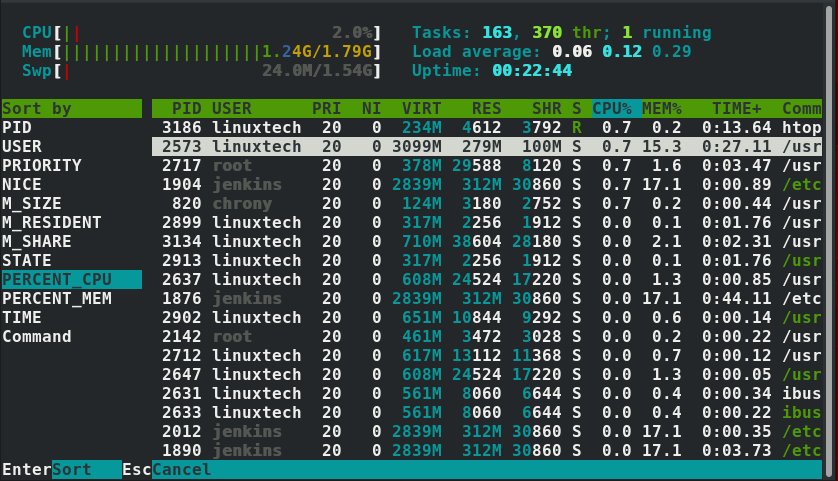
如果想使用内存使用率排序,就用下滑键选择 PERCENT_MEM 选项
linux进程通常都是层级顺序,会创建子进程,如果想显示子进程,按F5功能键就可以了。
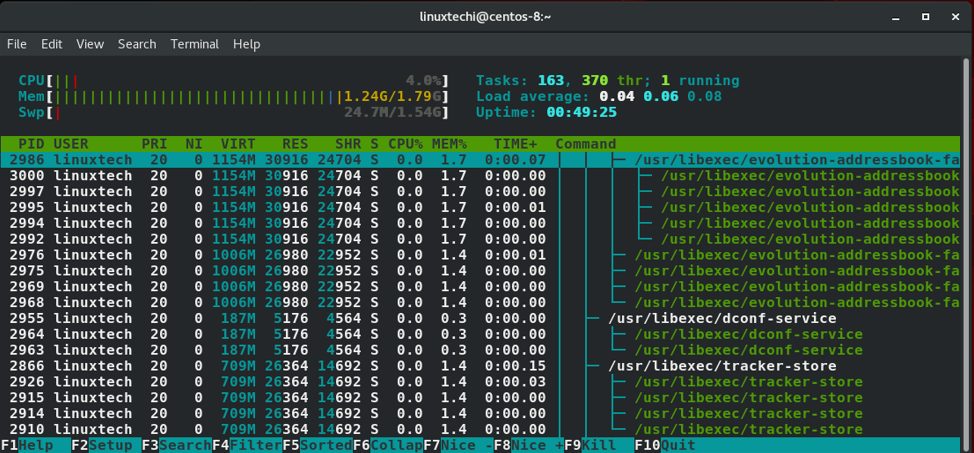
linux进程能依照他们各自的路径进行过滤。按下F4功能键就能过滤。这时就能在底部区域输入进程的路径。在下面的输出中。我展示了/urs/sbin这个路径的进程。
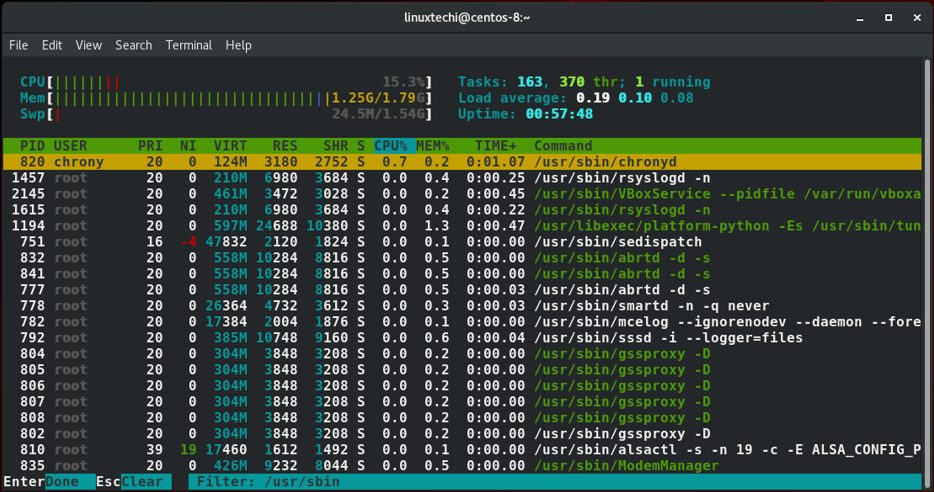
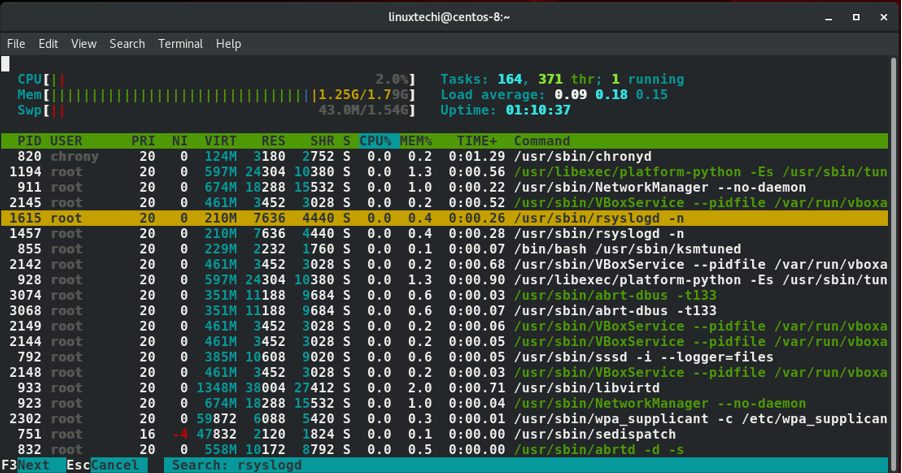
按下F3功能键之后你就能在终端的底部屏幕出现的区域输入进程的名字进行搜索。举例来说,在下面这个例子中,我输入了rsyslogd进程在 /usr/sbin路径中,找到之后进程就会以黄色高亮显示。
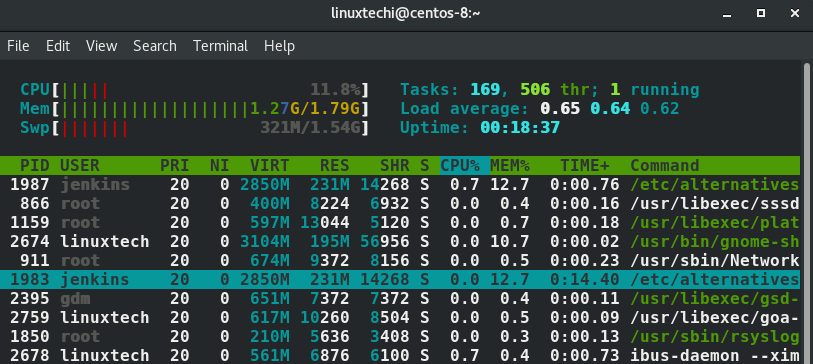
登陆htop之后滑动到你想要结束的进程上面。在这个例子中,我选择了jenkins,她的pid是1983
下一步,选择F9或者字母k之后就可以选择你想要发送的信号。在这个例子中,我选项了SIGKILL 来确保这个进程退出
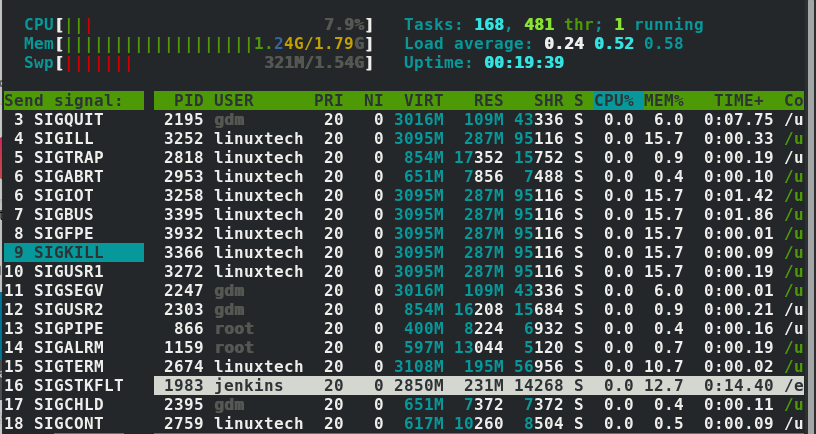
最后按下 ENTER 键
做一个微调就能确定你以怎样的格式输出,按下F2健。有几个选项可以改变例如颜色,字体样式,系统参数等等。
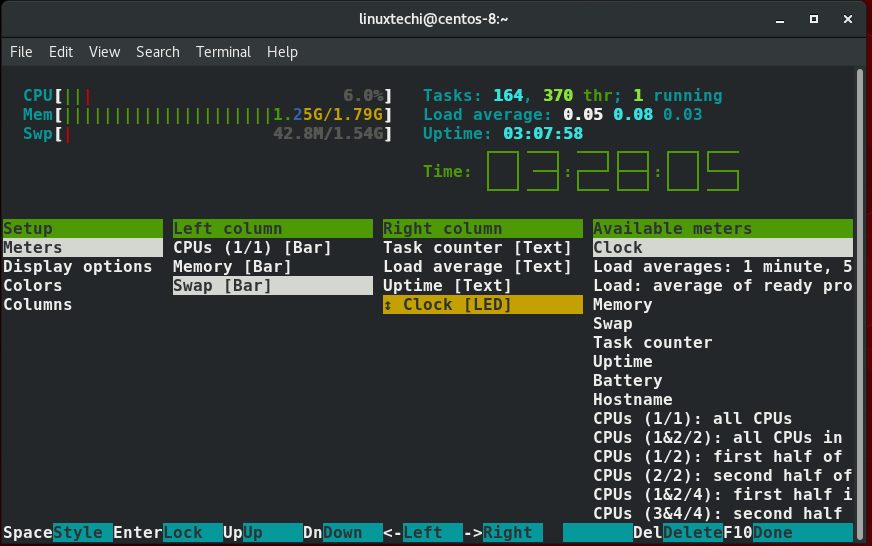
要获得有关如何使用htop查找路径以及如何最佳利用其中各种快捷方式的帮助,只需按F1键。各种快捷键列表和它们的作用将显示如下所示。
这就把我们带到htop命令这个主题的结尾了。欢迎评论并与你的朋友分享
原地址: https://mp.weixin.qq.com/s/lDXpxOzwUNHI_upVI83eFA
原作者: 远方青木(我非常佩服的一个牛人)
老家亲戚的孩子结婚,邀请他去喝喜酒。他欣然应允。回到了故乡,从车站走出来,他却有点恍惚了,喜宴是明天,他不知道是直奔亲戚家好,还是该先找个酒店住下,明天再赶过去?这是母亲过世后,他第一次返乡。父亲早年就过世了,3年前,母亲也走了。办完母亲的丧事,他在县城的妹妹家小住了几日。临别时,妹妹对他说:“哥,以后回来你就上我家住吧。”当时他点点头。但是,当他再次回来,站在熟悉却又陌生的车站出口,他忽然发觉,自己不知道该往哪去了。以前当然不是这样。
父母在时,每次回来,不管多晚,他都不担心,他会打个车,直奔县城20里外的家,那个他从小长大的乡村。有时候,他会提前告诉父母他要回来;有时,他也会忽然就出现在了家门口,让父母又惊又喜,嗔怪他搞突然袭击。也有时候,他并不急于回家,先到县城的妹妹家歇个脚,然后,再和妹妹全家,一大帮子人,浩浩荡荡地回乡。一到村头,就看见了手搭额头眺望的老母亲,露水打湿了她的裤脚,天知道她从几点就站在村口了,一定是妹妹提前告诉了老母亲。每次这样兴师动众地回来,陈旧的老宅,忽然被人声塞满,兴奋得吱吱作响。老宅只在他们回来时,才再一次呈现出欢乐、饱满的样子。这才是他熟悉的老宅的味道,家的味道。但这一次,他恍然不知去处。
他自然还可以像以往那样,先到妹妹家去。他和妹妹很亲,妹妹的儿女也和他这个舅舅很亲,但是,那终归是妹妹的家。以前落个脚,甚至小住几日,都没有关系,因为他是有自己的家的——父母在家里等着他,他随时可以回家。现在,再去妹妹家,就只能住那儿了,而不是中转一下,他真正成了一个借居的客人。想到这里,他突然提不起兴致去妹妹家。还是先回老屋看看吧。他在心里,用了老屋这个词,而不是家。父母不在了,那里也不是家了。他叫了辆车,回到老屋,对司机说,你在路边等等我,我还要回城的。老屋的一个墙角,已经坍塌。母亲去世后,他和妹妹们将母亲的遗物整理好,锁上门,就再也没有回来过。他绕着老屋转了几圈,残破的老屋,和心中那个家,一起坍塌一地。在村口,他遇见一位邻居。邻居说:“回……”话说了一半,又咽了回去,变成了邀请:“要不,上我家坐坐吧。”他谢了乡邻,那一刻,他意识到,对这个从小长大的村庄来说,他是客了。
他乘车回了城,入住一家酒店。犹豫了一下,他还是给妹妹打了电话,告诉她,他在县城,住在某某酒店。妹妹嗔怪说:“住什么酒店,咋不来家里住?”他讪笑无语。妹妹又说,“那你过来吃晚饭吧。”他答应了。在妹妹家楼下,遇见了买菜回来的妹妹。邻居看看他,对妹妹说:“家里来客了?”妹妹立即说:“什么客,我哥!”妹妹的话,让他感动,可是,他知道,那个邻居说的没错。在妹妹家,他是客;在故乡,他也是客。那天晚上,他喝了不少。回到酒店,迷迷糊糊接到儿子的电话,儿子问:“爸,你明天在家吗?我们回家来哦。”他告诉儿子:“我回老家了,但是,你妈在家呢。”
放下电话,他泪流满面。在家乡,他已是客了。但是,只要他在,妻子在,远方的家就还是儿子的家呢!
一般配置文件说明
user www www; #定义Nginx运行的用户和用户组
worker_processes auto; #nginx进程数,建议设置为等于CPU总核心数.一般设置成auto
error_log /opt/nginx/log/error.log warn; #全局错误日志定义类型,[ debug | info | notice | warn | error | crit ]
pid /var/run/nginx.pid; #进程文件
worker_rlimit_nofile 65535; #一个nginx进程打开的最多文件描述符数目,理论值应该是最多打开文件数(系统的值ulimit -n)与nginx进程数相除,但是nginx分配请求并不均匀,所以建议与ulimit -n的值保持一致.
#工作模式与连接数上限
events
{
use epoll; #参考事件模型,use [ kqueue | rtsig | epoll | /dev/poll | select | poll ]; epoll模型是Linux 2.6以上版本内核中的高性能网络I/O模型,如果跑在FreeBSD上面,就用kqueue模型.
worker_connections 65535; #单个进程最大连接数(最大连接数=连接数*进程数)
}
#设定http服务器
http
{
include mime.types; #文件扩展名与文件类型映射表
default_type application/octet-stream; #默认文件类型
charset utf-8; #默认编码
server_names_hash_bucket_size 128; #服务器名字的hash表大小
client_header_buffer_size 32k; #上传文件大小限制
large_client_header_buffers 4 64k; #设定请求缓
client_max_body_size 8m; #设定请求缓
# 开启目录列表访问,合适下载服务器,默认关闭.
autoindex on; # 显示目录
autoindex_exact_size on; # 显示文件大小 默认为on,显示出文件的确切大小,单位是bytes 改为off后,显示出文件的大概大小,单位是kB或者MB或者GB
autoindex_localtime on; # 显示文件时间 默认为off,显示的文件时间为GMT时间 改为on后,显示的文件时间为文件的服务器时间
sendfile on; # 开启高效文件传输模式,sendfile指令指定nginx是否调用sendfile函数来输出文件,对于普通应用设为 on,如果用来进行下载等应用磁盘IO重负载应用,可设置为off,以平衡磁盘与网络I/O处理速度,降低系统的负载.注意:如果图片显示不正常把这个改成off.
tcp_nopush on; # 防止网络阻塞
tcp_nodelay on; # 防止网络阻塞
keepalive_timeout 120; # (单位s)设置客户端连接保持活动的超时时间,在超过这个时间后服务器会关闭该链接
# FastCGI相关参数是为了改善网站的性能:减少资源占用,提高访问速度.下面参数看字面意思都能理解.
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
# gzip模块设置
gzip on; #开启gzip压缩输出
gzip_min_length 1k; #允许压缩的页面的最小字节数,页面字节数从header偷得content-length中获取.默认是0,不管页面多大都进行压缩.建议设置成大于1k的字节数,小于1k可能会越压越大
gzip_buffers 4 16k; #表示申请4个单位为16k的内存作为压缩结果流缓存,默认值是申请与原始数据大小相同的内存空间来存储gzip压缩结果
gzip_http_version 1.1; #压缩版本(默认1.1,目前大部分浏览器已经支持gzip解压.前端如果是squid2.5请使用1.0)
gzip_comp_level 5; #压缩等级.1压缩比最小,处理速度快.9压缩比最大,比较消耗cpu资源,处理速度最慢,但是因为压缩比最大,所以包最小,传输速度快
gzip_types text/plain application/x-javascript text/css application/xml; #压缩类型,默认就已经包含text/html,所以下面就不用再写了,写上去也不会有问题,但是会有一个warn.
gzip_vary on;#选项可以让前端的缓存服务器缓存经过gzip压缩的页面.例如:用squid缓存经过nginx压缩的数据
#虚拟主机的配置
server
{
listen 80; # 监听端口
server_name abc.com; # 域名可以有多个,用空格隔开
rewrite ^(.*) https://$server_name$1 permanent; # HTTP 自动跳转 HTTPS
}
server
{
listen 443 ssl; # 监听端口 HTTPS
server_name abc.com;
# 日志格式设定,
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $http_x_forwarded_for';
# 设置访问日志 access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]]; 下面指定日志的缓存大小为32k,日志写入前启用gzip进行压缩,压缩比使用默认值1,缓存数据有效时间为1分钟
access_log /opt/nginx/log/access.log main buffer=32k gzip flush=1m;
# 配置域名证书
ssl_certificate /opt/nginx/conf/cert/certificate.crt;
ssl_certificate_key /opt/nginx/conf/cert/private.key;
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 5m;
ssl_protocols SSLv2 SSLv3 TLSv1;
ssl_ciphers ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+EXP;
ssl_prefer_server_ciphers on;
index index.html index.htm index.php; ## 首页默认打开的文件
root /opt/www/; ## 项目的位置
location ~ .*\.(php|php5)?$
{
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi.conf;
}
# 配置地址拦截转发,解决跨域验证问题
location /mypath/{
proxy_pass https://localhost:8080/mypath/;
proxy_set_header HOST $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
# 图片缓存时间设置
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ {
expires 10d;
}
# JS和CSS缓存时间设置
location ~ .*\.(js|css)?$ {
expires 1h;
}
# 设定查看Nginx状态的地址.StubStatus模块能够获取Nginx自上次启动以来的工作状态,此模块非核心模块,需要在Nginx编译安装时手工指定才能使用
location /NginxStatus {
stub_status on;
access_log on;
auth_basic "NginxStatus";
auth_basic_user_file /opt/nginx/conf/htpasswd; #htpasswd文件的内容可以用apache提供的htpasswd工具来产生.
}
}
}
nginx作为负载均衡器时候的配置文件示例
events
{
use epoll;
worker_connections 65535;
}
http
{
##upstream的负载均衡,四种调度算法,调度算法1:轮询.每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某台服务器宕机,故障系统被自动剔除,使用户访问不受影响
upstream real_server1 {
server 192.168.0.2:8888 ;
server 192.168.0.3:8888 ;
}
#调度算法2:weight(权重).可以根据机器配置定义权重.权重越高被分配到的几率越大
upstream real_server2 {
server 192.168.0.4:8888 weight=2;
server 192.168.0.5:8888 weight=3;
}
#调度算法3:ip_hash. 每个请求按访问IP的hash结果分配,这样来自同一个IP的访客固定访问一个后端服务器,有效解决了动态网页存在的session共享问题
upstream real_server3 {
ip_hash;
server 192.168.0.6:8888 ;
server 192.168.0.7:8888 ;
}
#调度算法4:url_hash(需安装第三方插件).此方法按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率.Nginx本身是不支持url_hash的,如果需要使用这种调度算法,必须安装Nginx 的hash软件包
upstream real_server4 {
server 192.168.0.8:8888 ;
server 192.168.0.9:8888 ;
hash $request_uri;
}
#调度算法5:fair(需安装第三方插件).这是比上面两个更加智能的负载均衡算法.此种算法可以依据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间来分配请求,响应时间短的优先分配.Nginx本身是不支持fair的,如果需要使用这种调度算法,必须下载Nginx的upstream_fair模块
#虚拟主机的配置(采用调度算法3:ip_hash)
server
{
listen 80;
server_name www.example.com;
#对 "/" 启用反向代理
location / {
proxy_pass http://real_server3;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr; #后端的Web服务器可以通过X-Forwarded-For获取用户真实IP
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
#以下是一些反向代理的配置,可选.
proxy_set_header Host $host;
client_max_body_size 10m; #允许客户端请求的最大单文件字节数
client_body_buffer_size 128k; #缓冲区代理缓冲用户端请求的最大字节数,
proxy_connect_timeout 90; #nginx跟后端服务器连接超时时间(代理连接超时)
proxy_send_timeout 90; #后端服务器数据回传时间(代理发送超时)
proxy_read_timeout 90; #连接成功后,后端服务器响应时间(代理接收超时)
proxy_buffer_size 4k; #设置代理服务器(nginx)保存用户头信息的缓冲区大小
proxy_buffers 4 32k; #proxy_buffers缓冲区,网页平均在32k以下的设置
proxy_busy_buffers_size 64k; #高负荷下缓冲大小(proxy_buffers*2)
proxy_temp_file_write_size 64k; #设定缓存文件夹大小,大于这个值,将从upstream服务器传
}
}
}
参考网址: https://mp.weixin.qq.com/s/xmn8W3x1U2LlXUbeV2ZA_A